Big Data đang trở thành một phần thế mạnh và là tài sản rất lớn của mỗi công ty, tổ chức, cá nhân…, và Hadoop là một trong các công nghệ cốt lõi cho việc lưu trữ và truy cập dữ liệu lớn, đặc biệt là kiến trúc phân tán.
Bài Blog này sẽ trình bày sơ lược lý thuyết về Hadoop và cách cài đặt Hadoop trên hệ điều hành Windows.
Nội dung tài liệu gồm các phần dưới đây:
- Giới thiệu Hadoop
- Cài đặt Java JDK 1.8
- Thiết lập biến môi trường cho Java JDK
- Tải Hadoop và giải nén vào ổ C
- Thiết lập biến môi trường cho Hadoop
- Cấu hình các tập tin cho Hadoop
- Cập nhật các Hadoop Configurations
- Hoàn thành cài đặt Hadoop và test thử nghiệm với start-all.cmd
Lưu ý: Mọi thư mục cài đặt: Không có dấu + không có khoảng trắng
Mục 1. Giới thiệu Hadoop, bài Blog này tham khảo từ:
- mastercode.vn
- bigdataviet.wordpress.com
- topdev.vn
Phần cài đặt Hadoop tham khảo từ:
- brain-mentors.com
Cuối bài viết Tui có để file PDF tổng hợp toàn bộ bài này để các bạn tải về làm tư liệu nếu cần.
Mấy lý thuyết phần giới thiệu này có nhiều trên mạng, các bạn có thể tìm kiếm thấy nó rất nhiều. Tui tổng hợp tóm tắt lại thôi nha (Không phải Tui tự nghĩ ra, các link tham khảo đã nói ở trên. Tui chỉnh sửa lại bố cục xíu cho phù hợp với bài blog hướng dẫn).
1.1 Hadoop là gì?
Hadoop là một Apache framework mã nguồn mở cho phép phát triển các ứng dụng phân tán để lưu trữ và quản lý các tập dữ liệu lớn. Hadoop hiện thực mô hình MapReduce, mô hình mà ứng dụng sẽ được chia nhỏ ra thành nhiều phân đoạn khác nhau được chạy song song trên nhiều node khác nhau.
Hadoop được viết bằng Java tuy nhiên vẫn hỗ trợ C++, Python, Perl bằng cơ chế streaming.
Hadoop có các điểm lợi sau:
- Robus and Scalable – Có thể thêm node mới và thay đổi chúng khi cần.
- Affordable and Cost Effective – Không cần phần cứng đặc biệt để chạy Hadoop.
- Adaptive and Flexible – Hadoop được xây dựng với tiêu chí xử lý dữ liệu có cấu trúc và không cấu trúc.
- Highly Available and Fault Tolerant – Khi 1 node lỗi, nền tảng Hadoop tự động chuyển sang node khác.
1.2 Chức năng nhiệm vụ của Hadoop
- Xử lý và làm việc khối lượng dữ liệu khổng lồ tính bằng Petabyte.
- Xử lý trong môi trường phân tán, dữ liệu lưu trữ ở nhiều phần cứng khác nhau, yêu cầu xử lý đồng bộ
- Các lỗi xuất hiện thường xuyên.
- Băng thông giữa các phần cứng vật lý chứa dữ liệu phân tán có giới hạn.
Một cụm Hadoop nhỏ gồm 1 master node và nhiều worker/slave node. Toàn bộ cụm chứa 2 lớp, một lớp MapReduce Layer và lớp kia là HDFS Layer. Mỗi lớp có các thành phần liên quan riêng. Master node gồm JobTracker, TaskTracker, NameNode, và DataNode. Slave/worker node gồm DataNode, và TaskTracker. Cũng có thể slave/worker node chỉ là dữ liệu hoặc node để tính toán.

Hadoop framework gồm 4 module:
Module 1: Hadoop Distributed File System (HDFS)
Đây là hệ thống file phân tán cung cấp truy cập thông lượng cao cho ứng dụng khai thác dữ liệu. Hadoop Distributed File System (HDFS) là hệ thống tập tin ảo. Khi chúng ta di chuyển 1 tập tin trên HDFS, nó tự động chia thành nhiều mảnh nhỏ. Các đoạn nhỏ của tập tin sẽ được nhân rộng và lưu trữ trên nhiều máy chủ khác để tăng sức chịu lỗi và tính sẵn sàng cao.
HDFS sử dụng kiến trúc master/slave, trong đó master gồm một NameNode để quản lý hệ thống file metadata và một hay nhiều slave DataNodes để lưu trữ dữ liệu thực tại.
Một tập tin với định dạng HDFS được chia thành nhiều khối và những khối này được lưu trữ trong một tập các DataNodes. NameNode định nghĩa ánh xạ từ các khối đến các DataNode. Các DataNode điều hành các tác vụ đọc và ghi dữ liệu lên hệ thống file. Chúng cũng quản lý việc tạo, huỷ, và nhân rộng các khối thông qua các chỉ thị từ NameNode.
Module 2: Hadoop MapReduce
Đây là hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn. Là cách chia một vấn đề dữ liệu lớn hơn thành các đoạn nhỏ hơn và phân tán nó trên nhiều máy chủ. Mỗi máy chủ có 1 tập tài nguyên riêng và máy chủ xử lý dữ liệu trên cục bộ. Khi máy chủ xử lý xong dữ liệu, chúng sẽ gởi trở về máy chủ chính.
MapReduce gồm một single master (máy chủ) JobTracker và các slave (máy trạm) TaskTracker trên mỗi cluster-node. Master có nhiệm vụ quản lý tài nguyên, theo dõi quá trình tiêu thụ tài nguyên và lập lịch quản lý các tác vụ trên các máy trạm, theo dõi chúng và thực thi lại các tác vụ bị lỗi. Những máy slave TaskTracker thực thi các tác vụ được master chỉ định và cung cấp thông tin trạng thái tác vụ (task-status) để master theo dõi.
JobTracker là một điểm yếu của Hadoop Mapreduce. Nếu JobTracker bị lỗi thì mọi công việc liên quan sẽ bị ngắt quãng.
Module 3: Hadoop Common
Đây là các thư viện và tiện ích cần thiết của Java để các module khác sử dụng. Những thư viện này cung cấp hệ thống file và lớp OS trừu tượng, đồng thời chứa các mã lệnh Java để khởi động Hadoop.
Module 4: Hadoop YARN
Quản lý tài nguyên của các hệ thống lưu trữ dữ liệu và chạy phân tích.
1.4 Cơ chế hoạt động của Hadoop
Giai đoạn 1:
Một user hay một ứng dụng có thể submit một job lên Hadoop (hadoop job client) với yêu cầu xử lý cùng các thông tin cơ bản:
Nơi lưu (location) dữ liệu input, output trên hệ thống dữ liệu phân tán.
Các java class ở định dạng jar chứa các dòng lệnh thực thi các hàm map và reduce.
Các thiết lập cụ thể liên quan đến job thông qua các thông số truyền vào.
Giai đoạn 2:
Hadoop job client submit job (file jar, file thực thi) và các thiết lập cho JobTracker. Sau đó, master sẽ phân phối tác vụ đến các máy slave để theo dõi và quản lý tiến trình các máy này, đồng thời cung cấp thông tin về tình trạng và chẩn đoán liên quan đến job-client.
Giai đoạn 3:
TaskTrackers trên các node khác nhau thực thi tác vụ MapReduce và trả về kết quả output được lưu trong hệ thống file.
Khi “chạy Hadoop” có nghĩa là chạy một tập các trình nền – daemon, hoặc các chương trình thường trú, trên các máy chủ khác nhau trên mạng của bạn. Những trình nền có vai trò cụ thể, một số chỉ tồn tại trên một máy chủ, một số có thể tồn tại trên nhiều máy chủ.
Các daemon bao gồm:
- NameNode
- DataNode
- SecondaryNameNode
- JobTracker
- TaskTracker
2. Cài đặt JDK bản 1.8 (bắt buộc)
Hadoop sử dụng JDK 1.8
Ta vào link sau:
https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html
Ví dụ cài bản Java SE Development Kit 8u201:
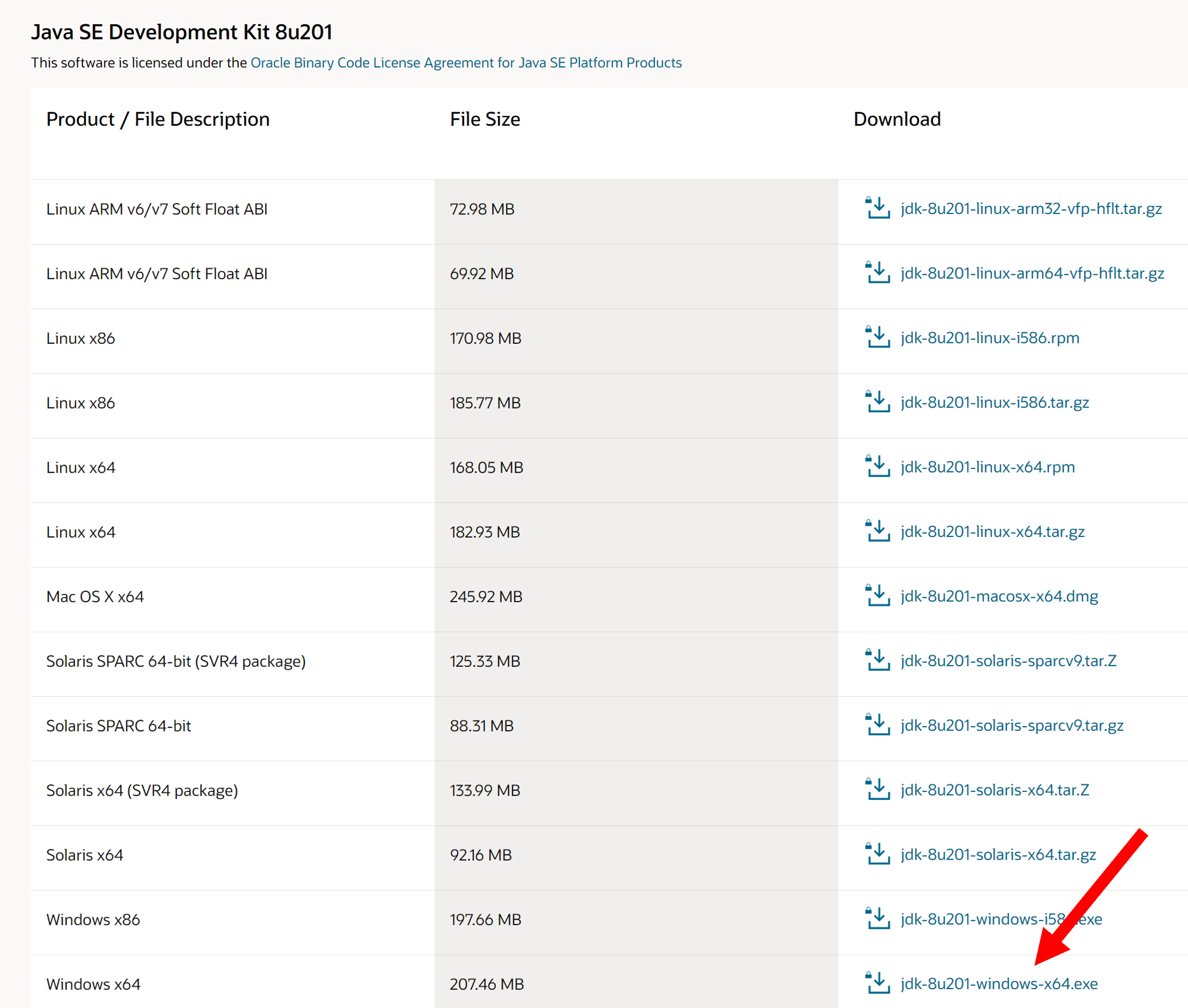
Bấm vào link để tải, chương trình xuất hiện như bên dưới:
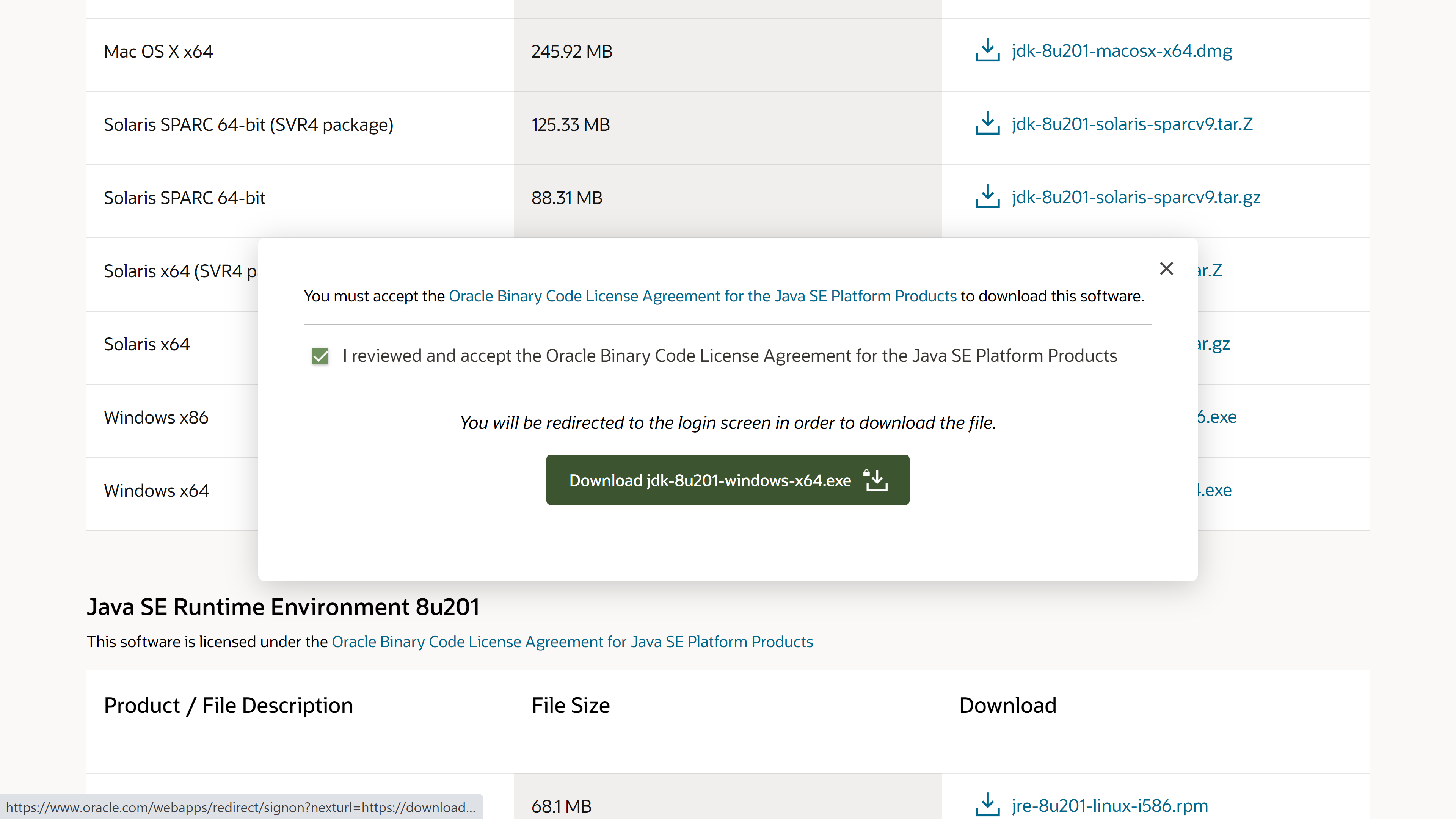
Tick vào “I reviewed and accept the Oracle….”
Rồi bấm download
Chương trình yêu cầu đăng nhập:
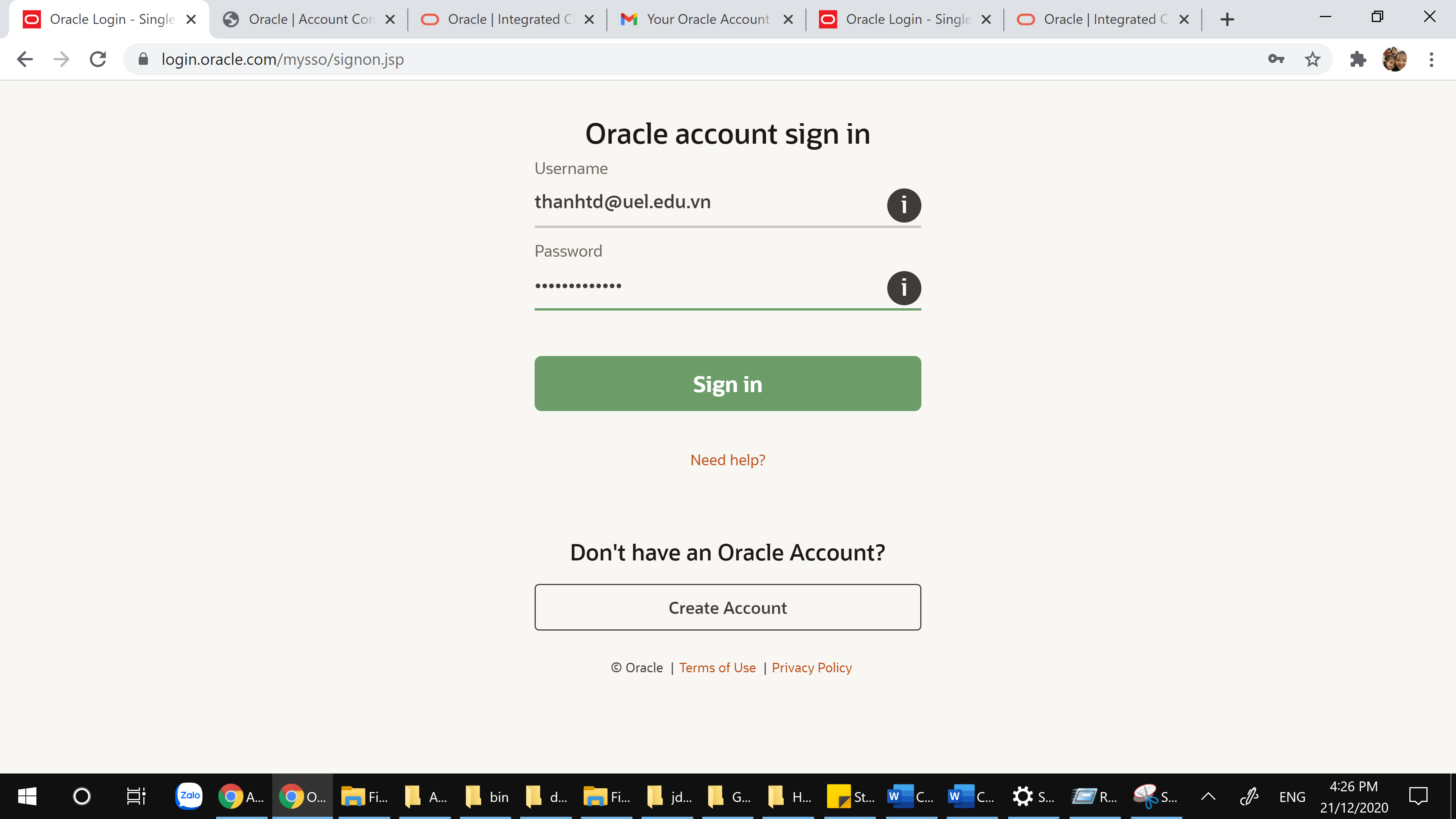
Nếu chưa có tài khoản thì cứ đăng ký “Create Account”
Khi đăng nhập thành công, Oracle sẽ hỏi nơi lưu trữ file tải:
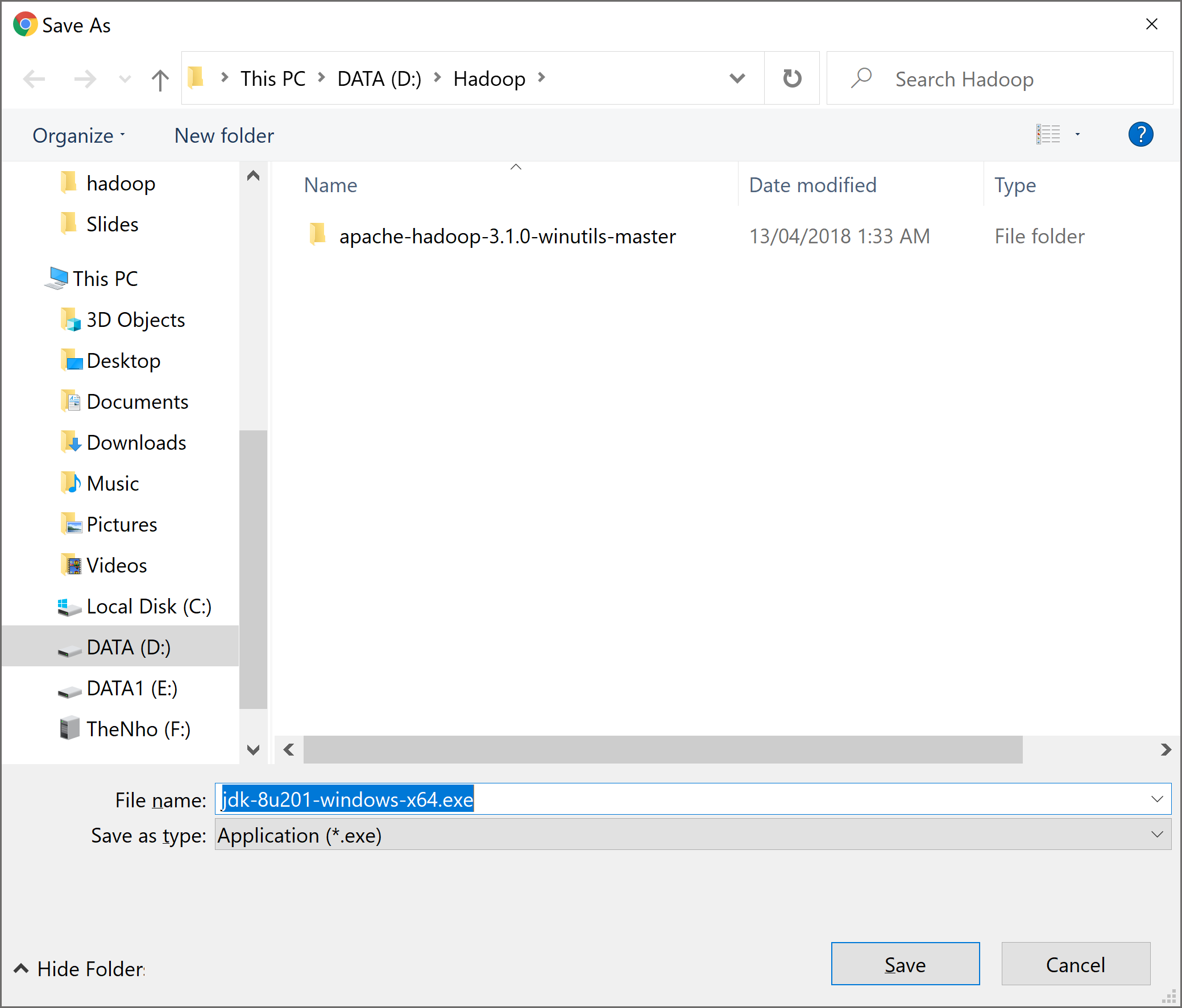
Ta chọn nơi lưu trữ rồi bấm Save

Ở trên ta có được JDK version 8u21, dung lượng khoảng 212MB
Tiến hành cài đặt:
Double click vào file vừa tải về:

Nhấn Next để cài đặt
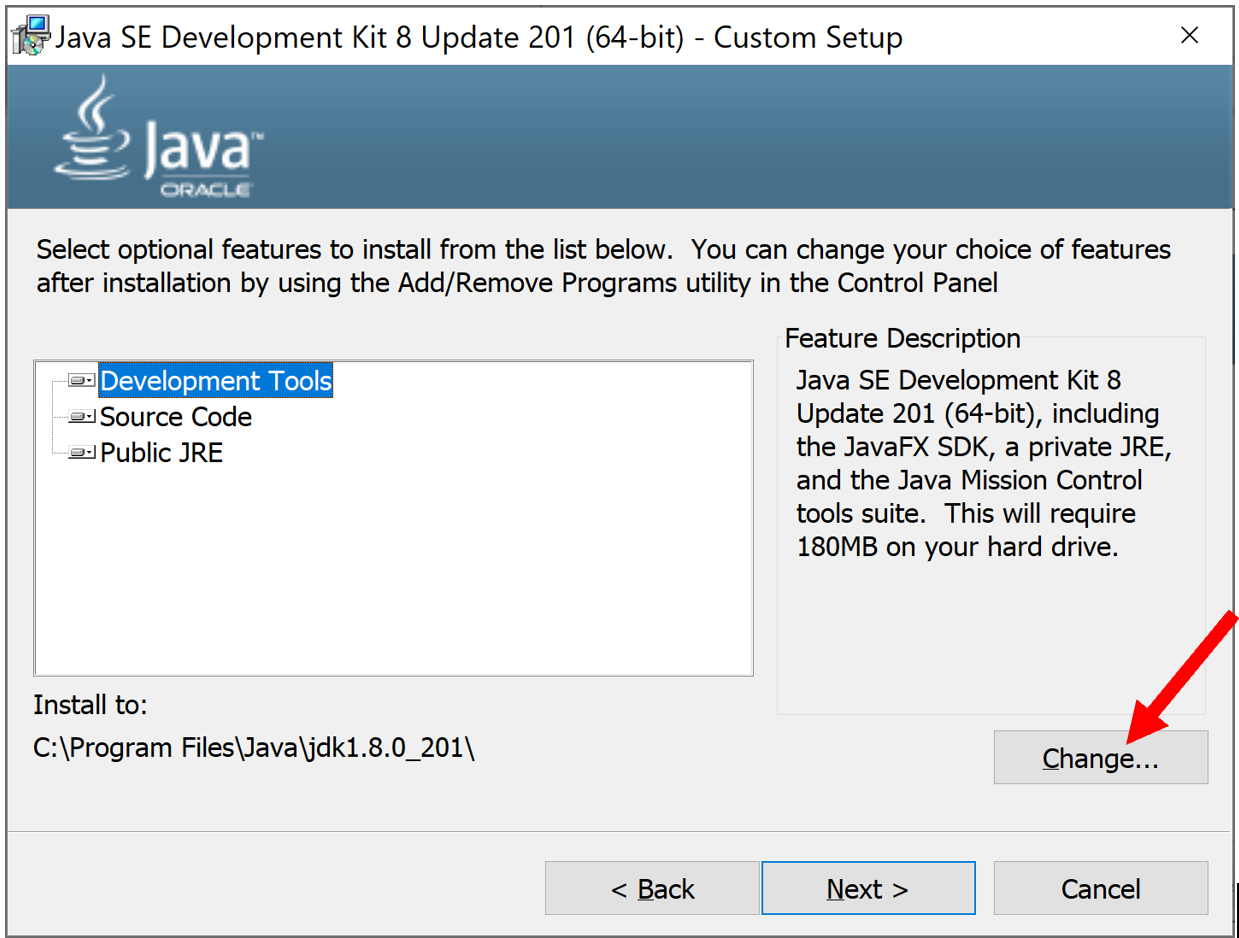
Tới chỗ này nhớ chỉnh vào Ổ C, không có dấu và không khoảng trắng
Sau đó nhấn OK

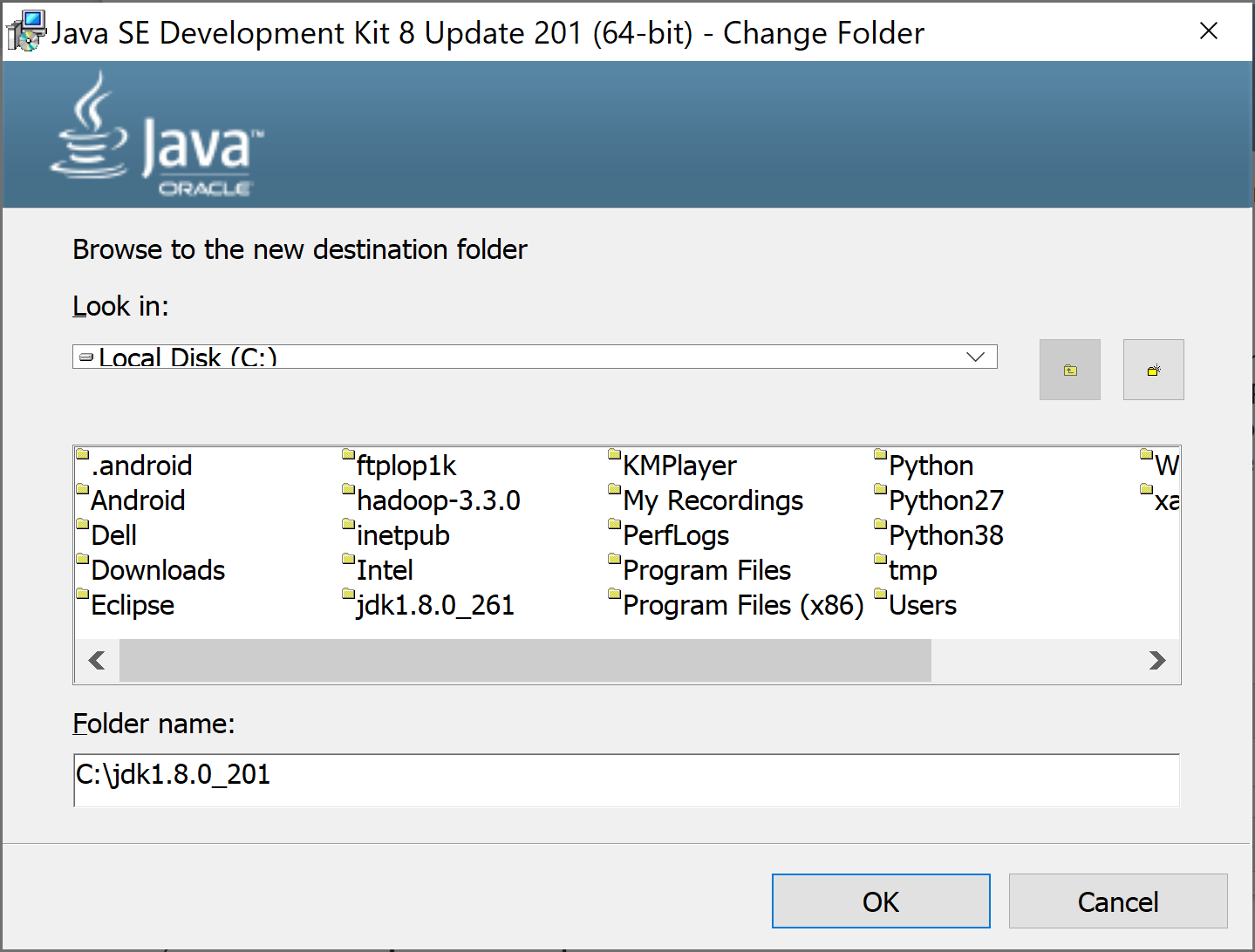
Chọn được nơi cài JDK không có khoảng trắng, nhấn Next để tiếp tục
Chờ chương trình cài đặt hoàn tất
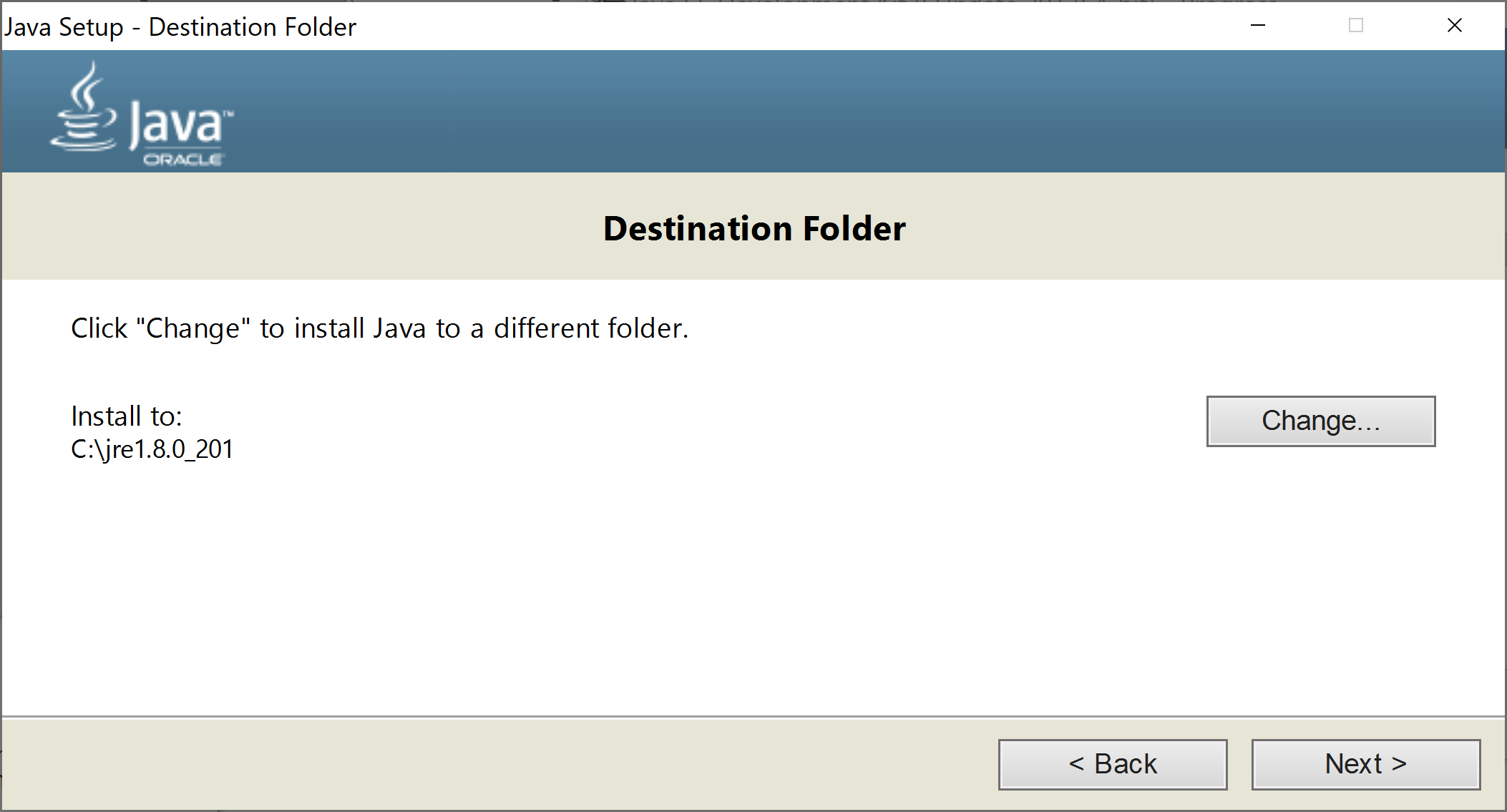
Nếu jre yêu cầu cài thì cũng chỉnh vào ổ C như trên
Bấm Next
và Tiếp tục chờ

Khi xuất hiện màn hình dưới đây tức là đã hoàn tất quá trình cài đặt JDK
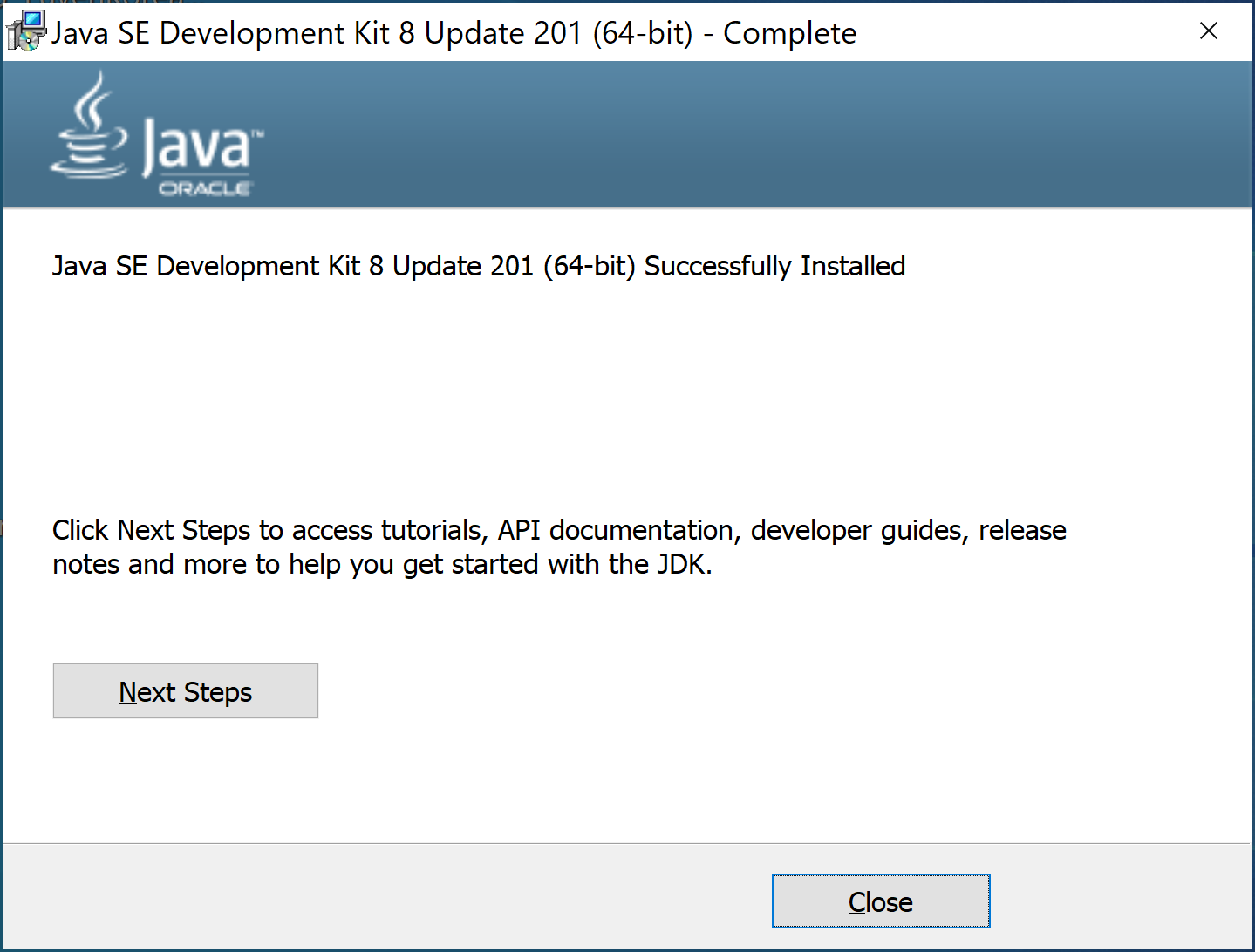
Bấm Close để hoàn tất
Như vậy đã cài đặt xong JDK 1.8
3) Thiết lập biến môi trường cho Java JDK
Cần cấu hình biến môi trường JAVA_HOME cho Java JDK

Bấm chuột phải vào Computer / chọn Properties
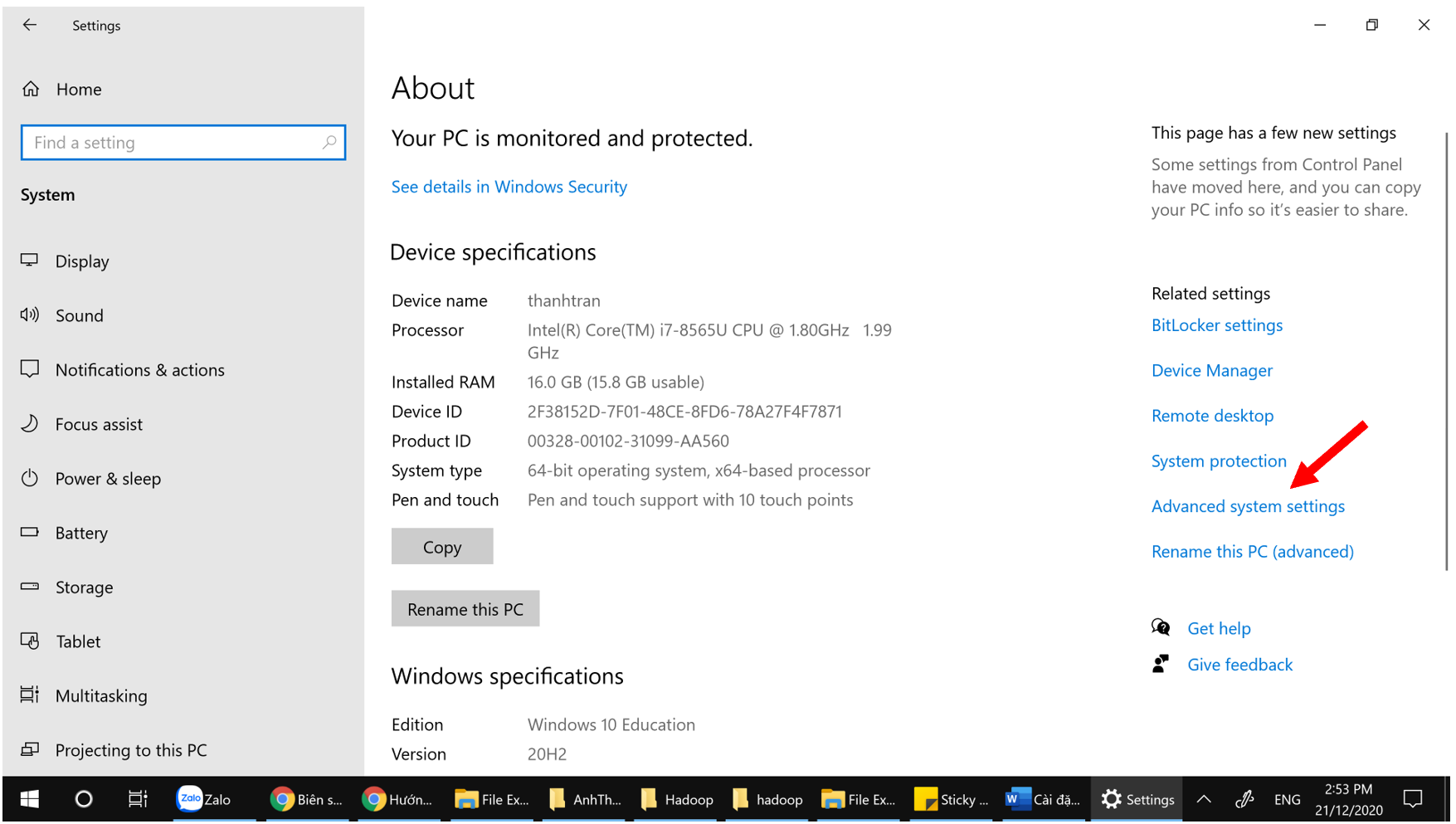
Chọn Advanced System Settings
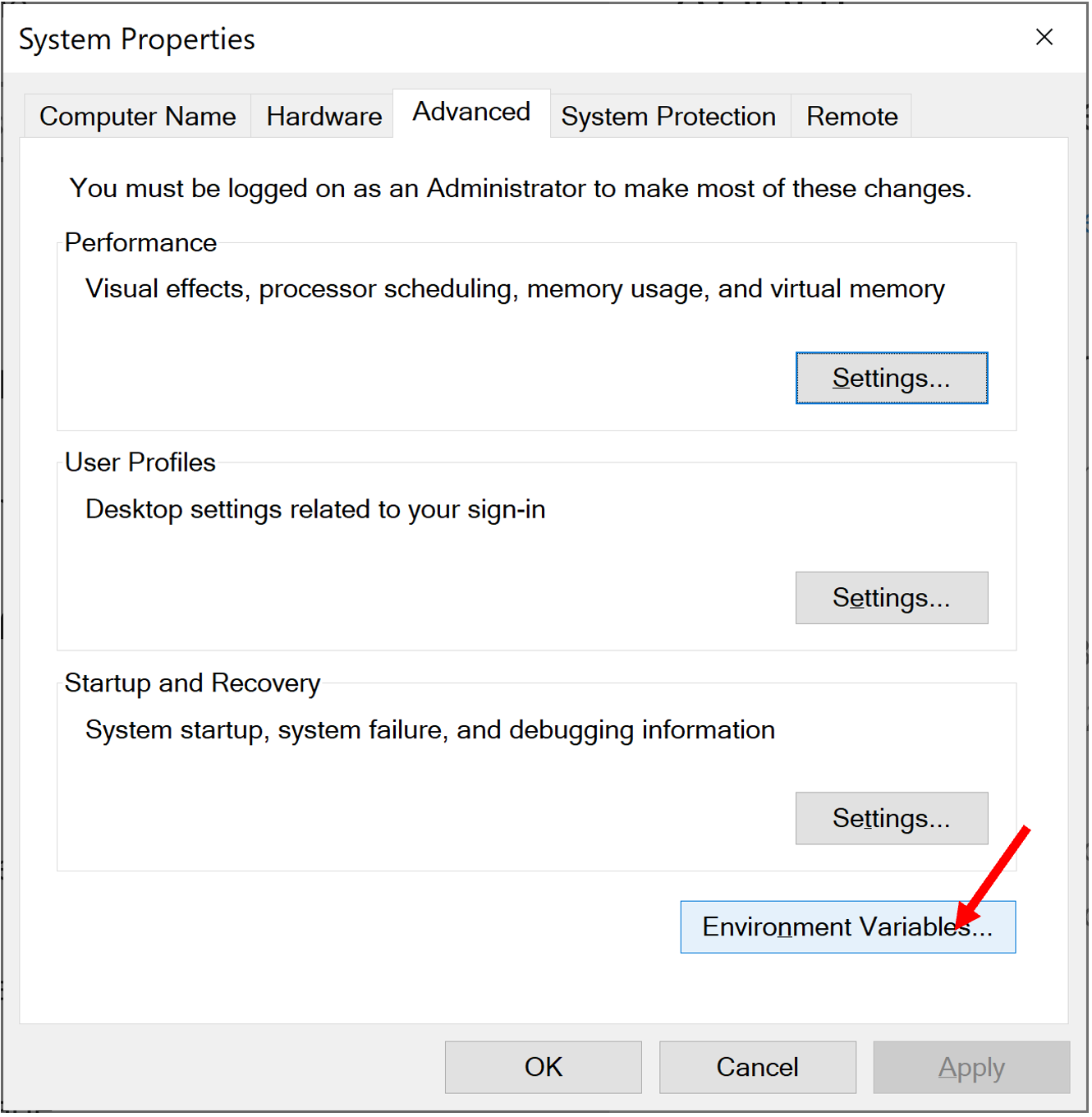
Chọn Environment Variables…
Màn hình Environment Variables sẽ xuất hiện như dưới đây:
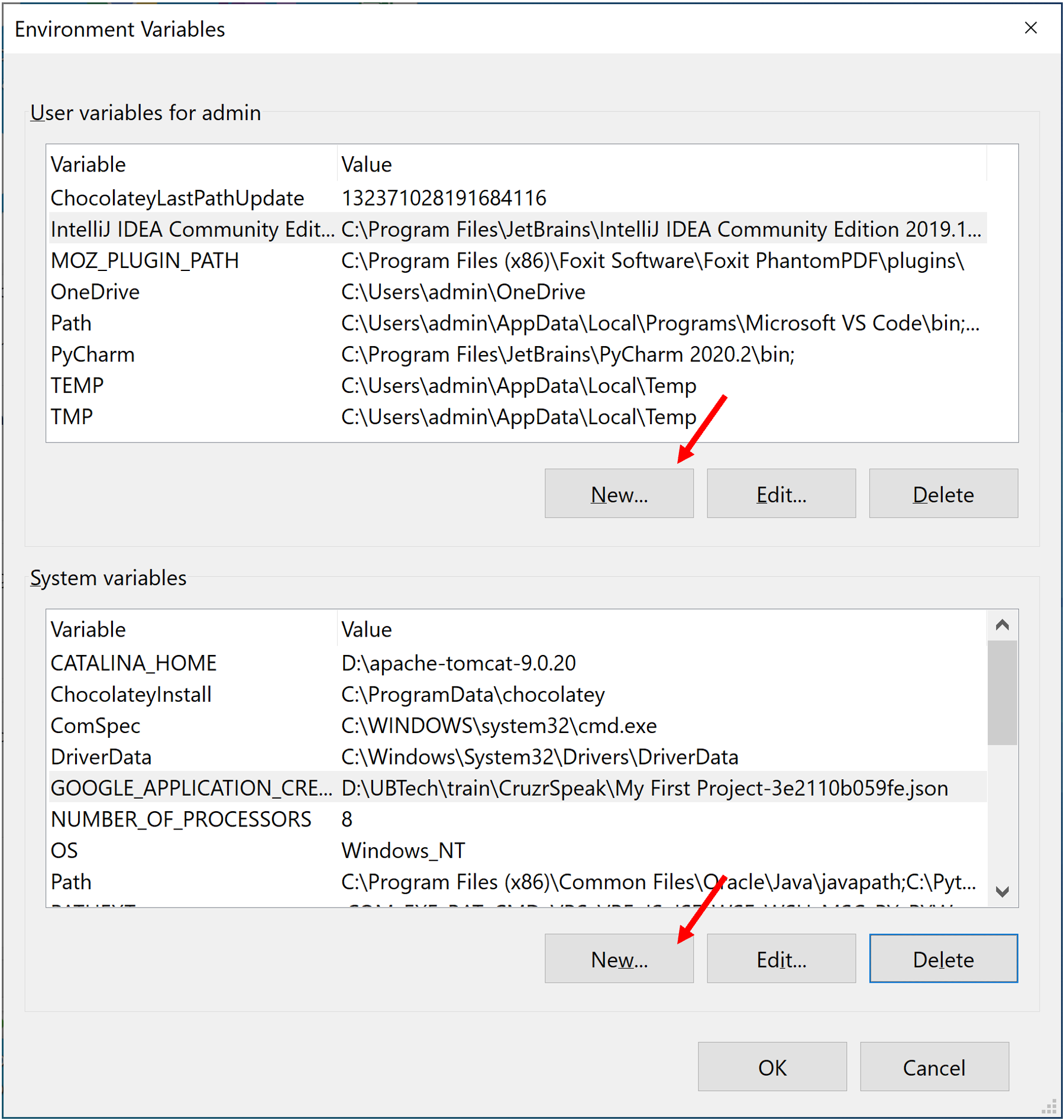
Trong mục user và system variables ta cấu hình JAVA_HOME trỏ tới nơi cài đặt JDK (bằng cách nhấn vào nút New…)
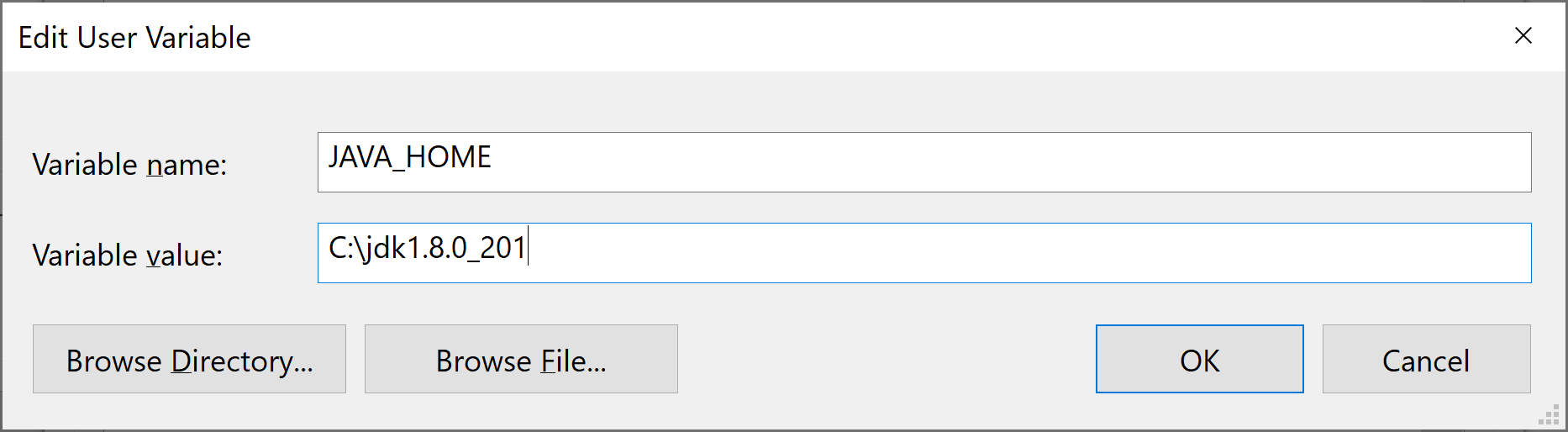
Variable name: JAVA_HOME
Variable value: C:\jdk1.8.0_201
Sau đó nhấn OK
Kết quả:
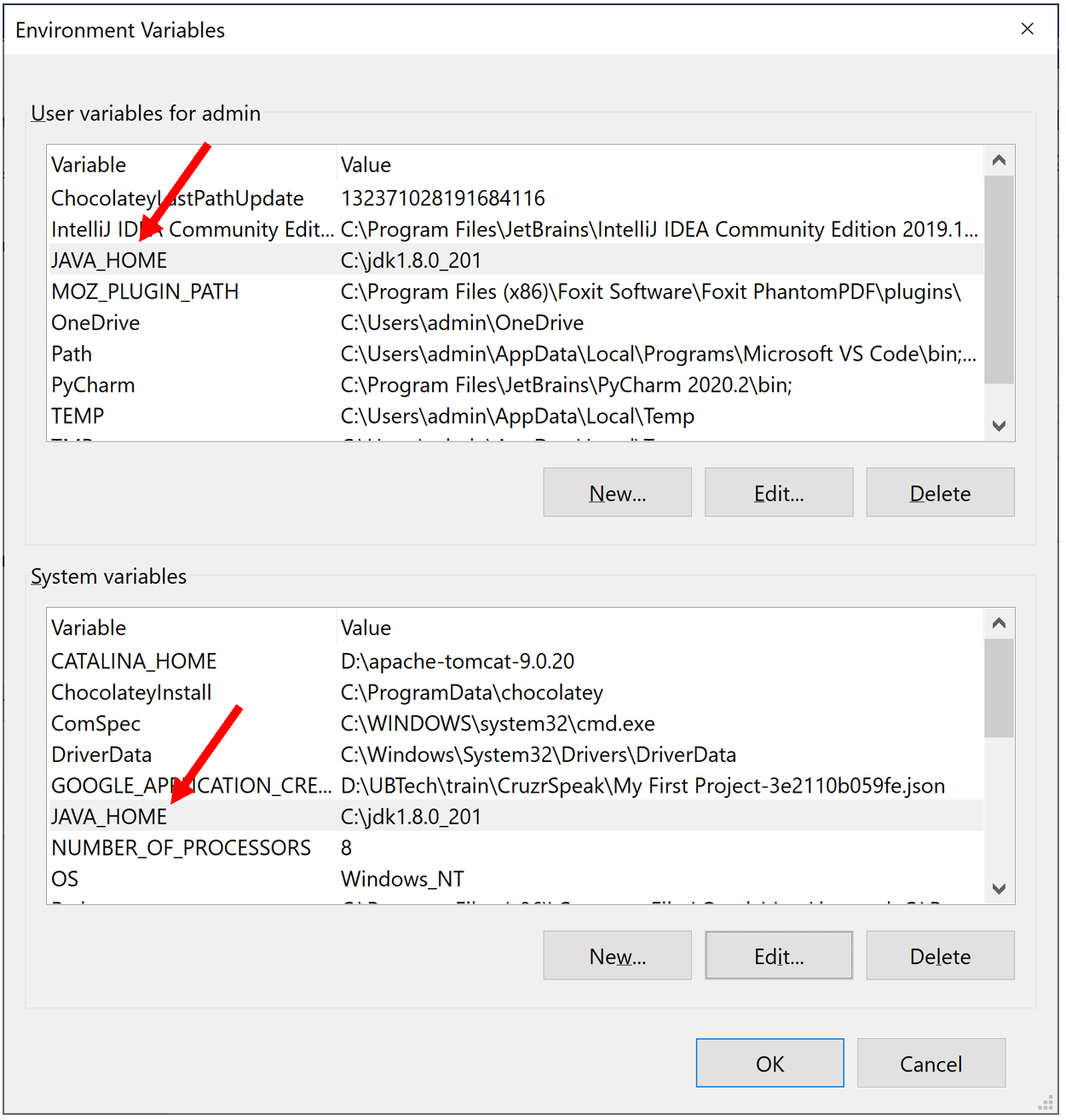
Sau đó bấm OK liên tục để đóng các cửa sổ cũng như xác nhận sự thay đổi
Tiếp theo cấu hình Path (cho cả user và system variable). Tìm tới biến Path, nhấn Edit:
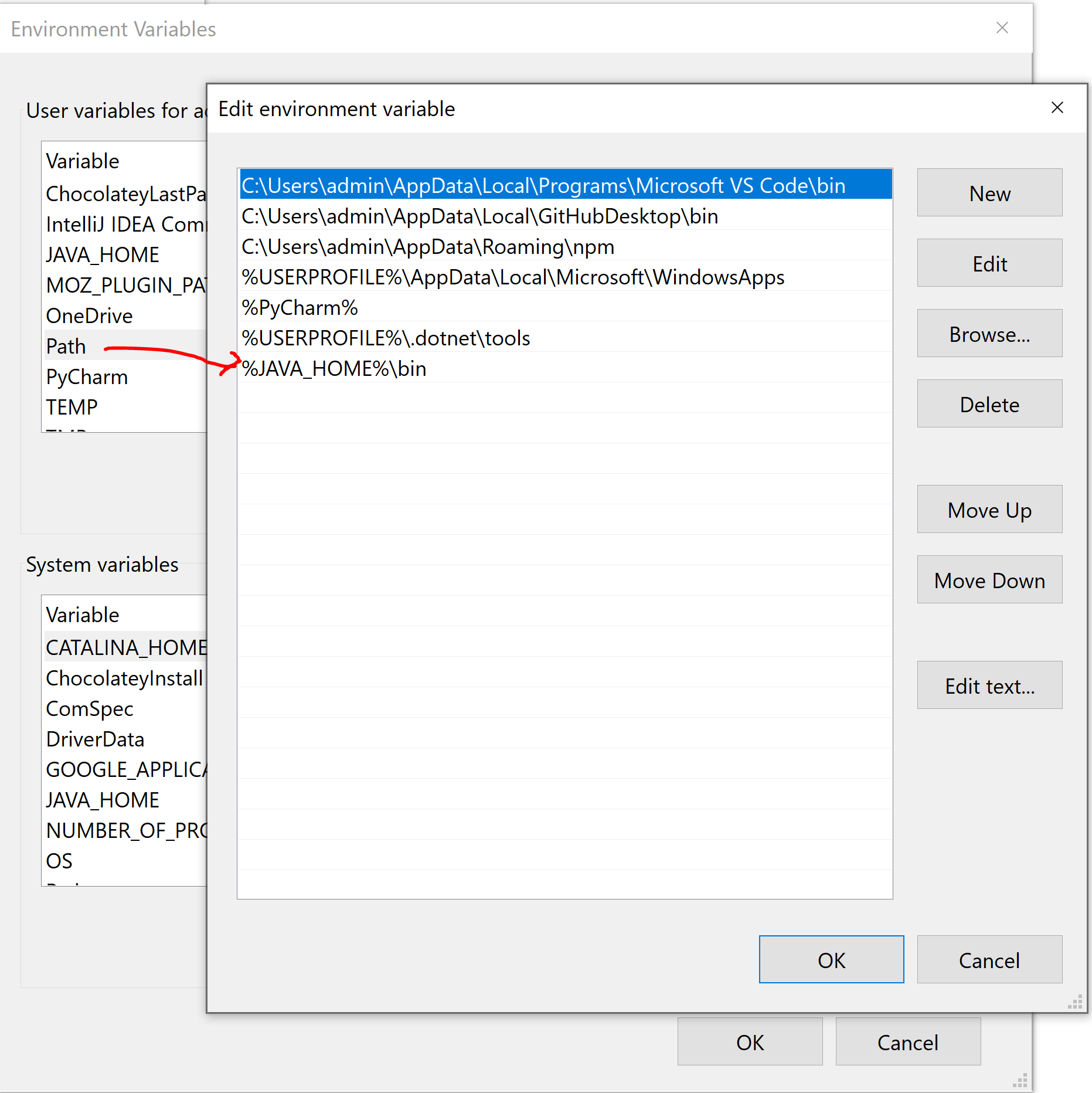
Thêm lệnh: %JAVA_HOME%\bin
nhấn OK
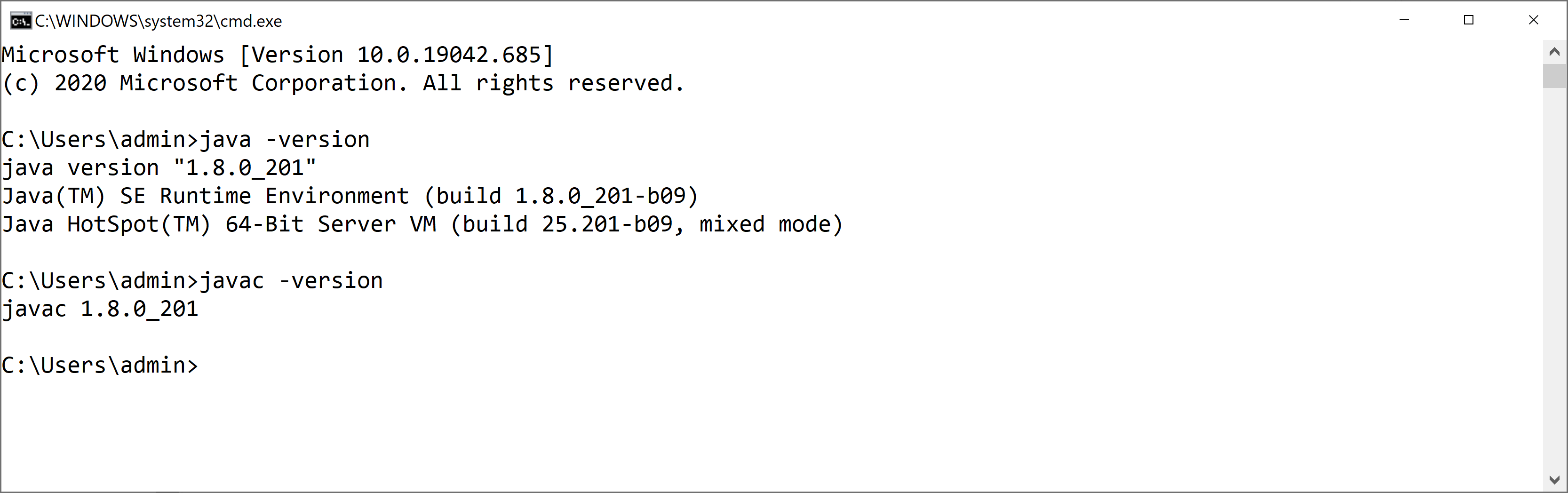
Kiểm tra lại quá trình cấu hình bằng cách Gõ phím Windows +R–>gõ cmd:
Trong màn hình command line lên gõ các lệnh trên để thấy kết quả:
java -version
javac -version
Kết quả:
4) Tải Hadoop và giải nén vào ổ C
Vào link sau tải hadoop 3.3.0 về:
https://mirror.downloadvn.com/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
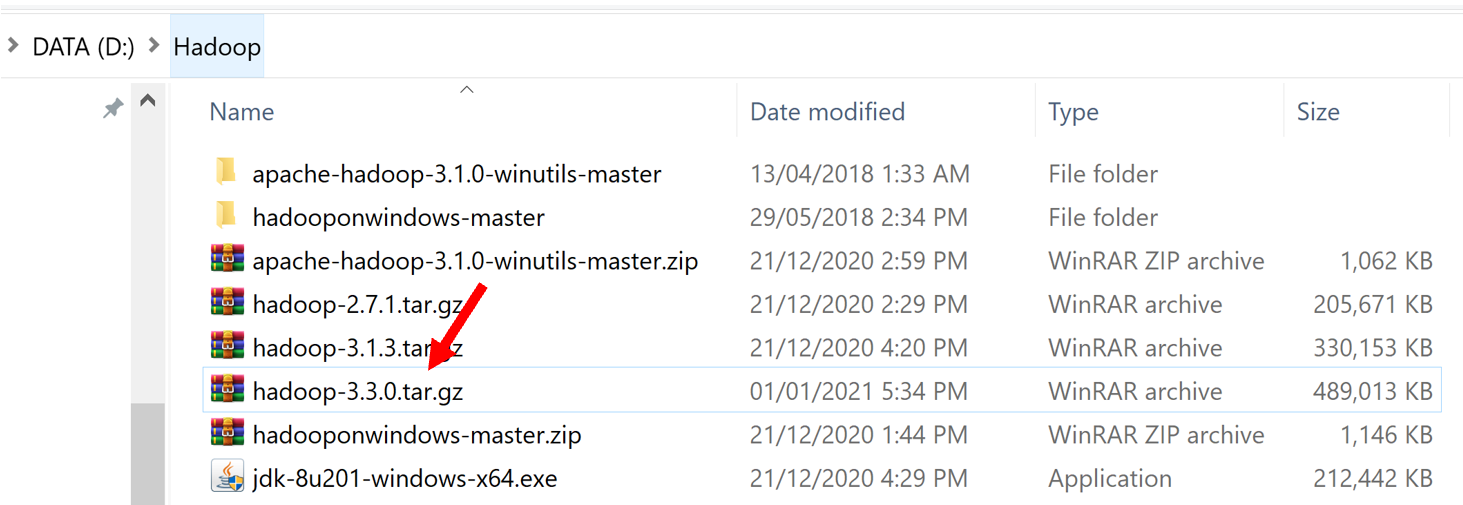
Giải nén vào ổ C
Bấm chuột phải vào “hadoop-3.3.0.tar.gz”
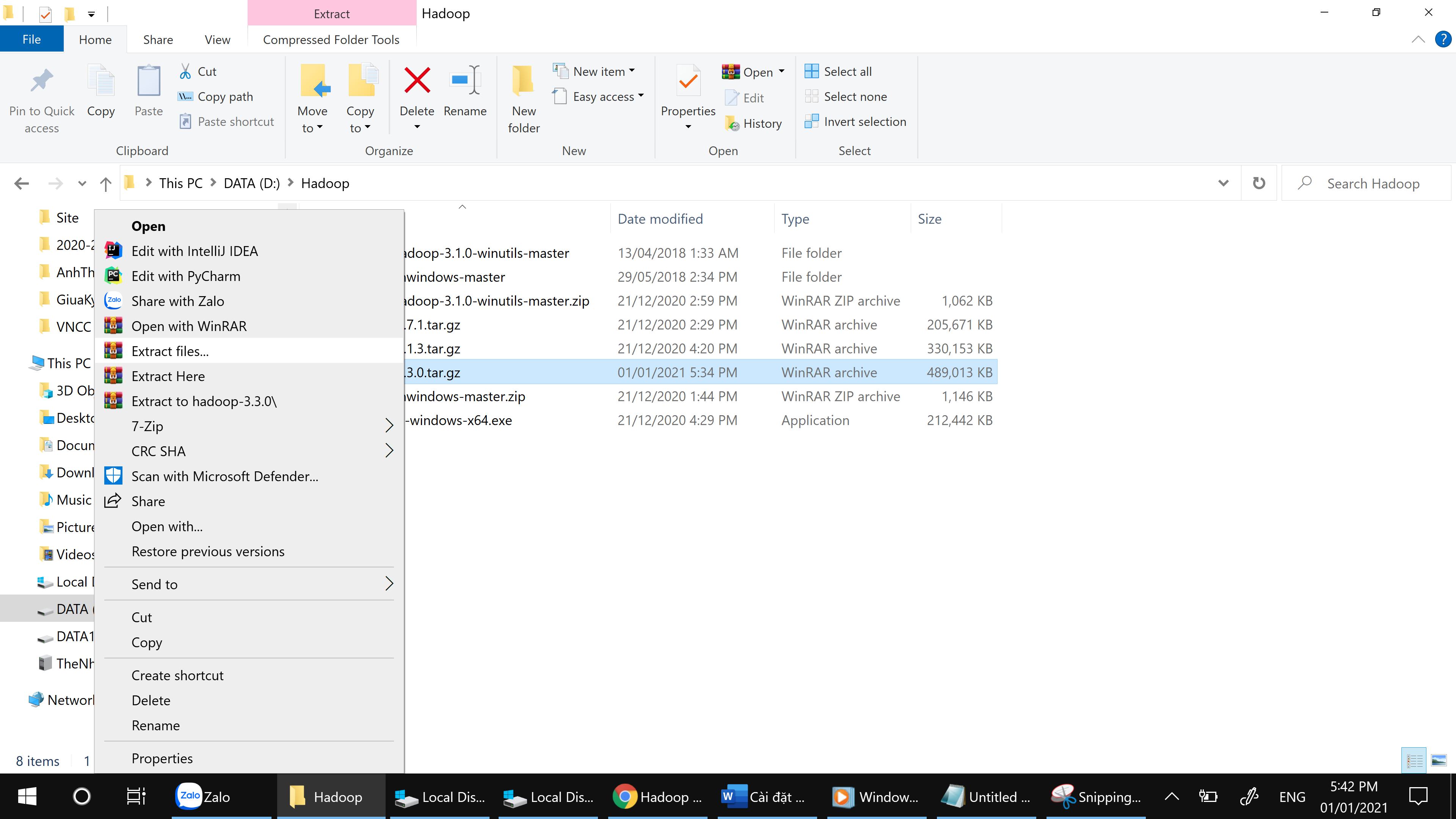
Chọn Extract files…

Chỉnh qua Ổ C rồi bấm OK:
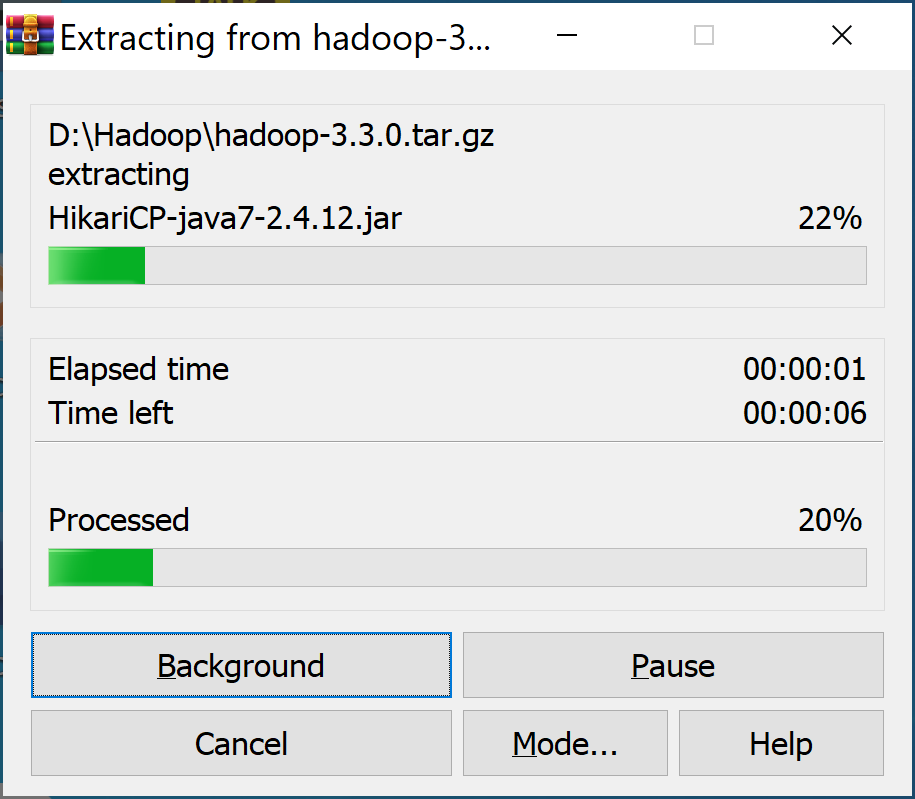
Mở ổ C lên–>thấy thư mục hadoop-3.3.0
5) Thiết lập biến môi trường cho Hadoop
Tương tự như JAVA JDK, ta cần cấu hình biến môi trường cho Hadoop (HADOOP_HOME)
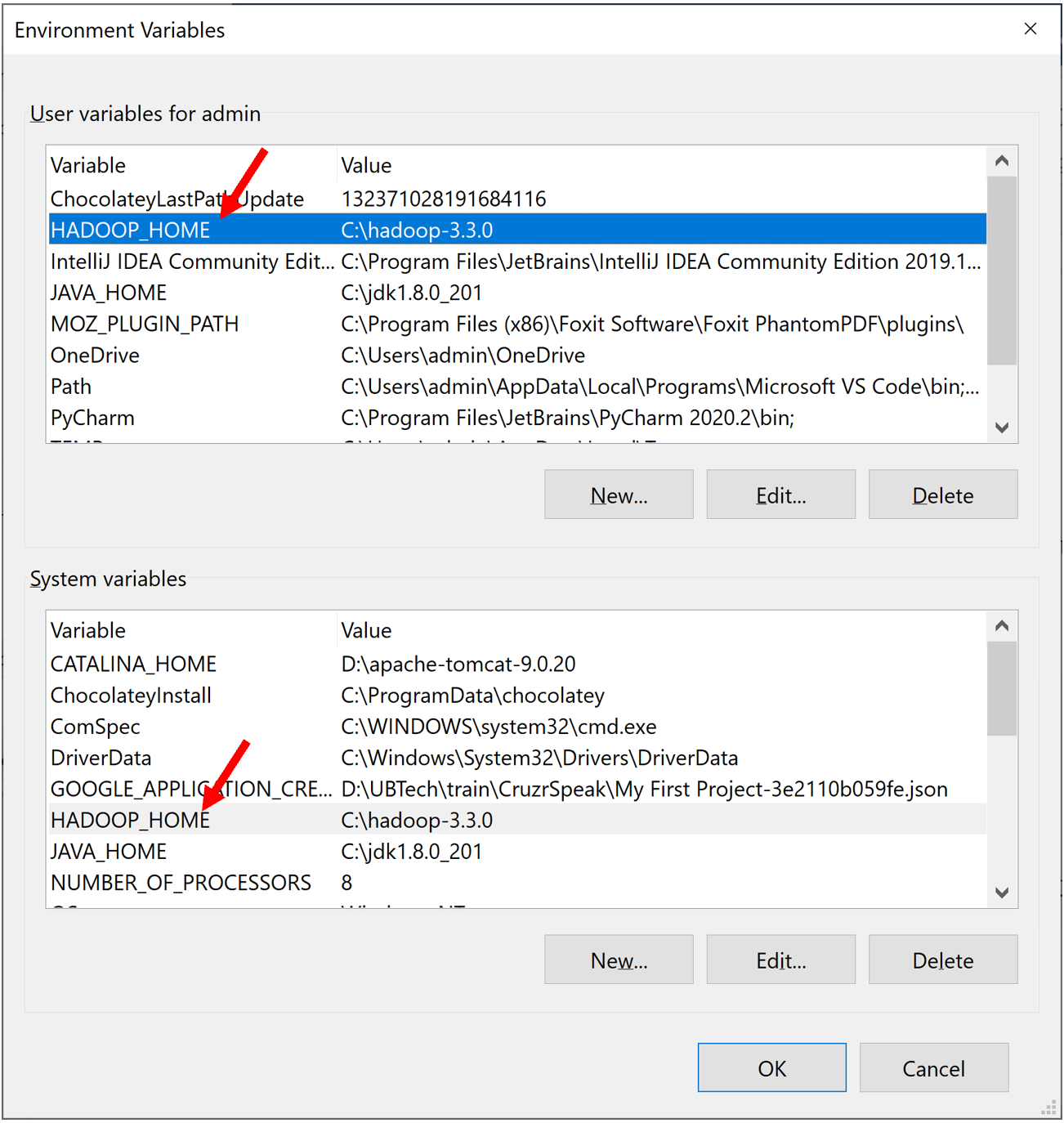
Lần lượt trong user và system variable thêm biến HADOOP_HOME có giá trị là C:\hadoop-3.3.0 mà ta giải nén ở trên.
Sau đó chỉnh sửa biến path cho cả user và system variable. Bổ sung thêm:

%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
Nhấn Ok để đóng tất cả các cửa sổ
Mở CMD để test lại:
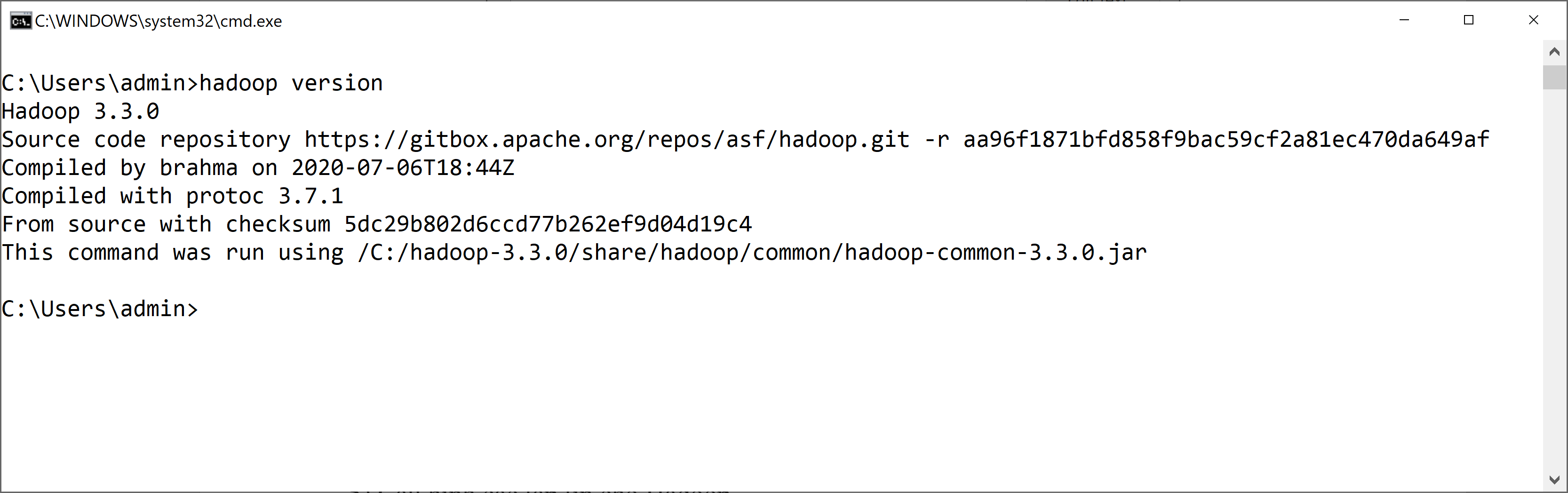
Gõ lệnh: hadoop version
Ta thấy kết quả là hadoop có version 3.3.0, như vậy cấu hình biến môi trường đã xong.
6) Cấu hình các tập tin cho Hadoop
Trong thư mục C:/Hadoop-3.3.0/etc/hadoop lần lượt chỉnh sửa các file:
- core-site.xml
- mapred-site.xml
- hdfs-site.xml
- yarn-site.xml
- hadoop-env.cmd
Cấu hình core-site.xml như dưới đây:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>Cấu hình mapred-site.xml như dưới đây:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Cấu hình hdfs-site.xml như dưới đây:
Tạo thư mục “data” trong “C:/Hadoop-3.3.0”
Tạo thư mục con “datanode” trong “C:/Hadoop-3.3.0/data”
Tạo thư mục con “namenode” trong “C:/Hadoop-3.3.0/data”
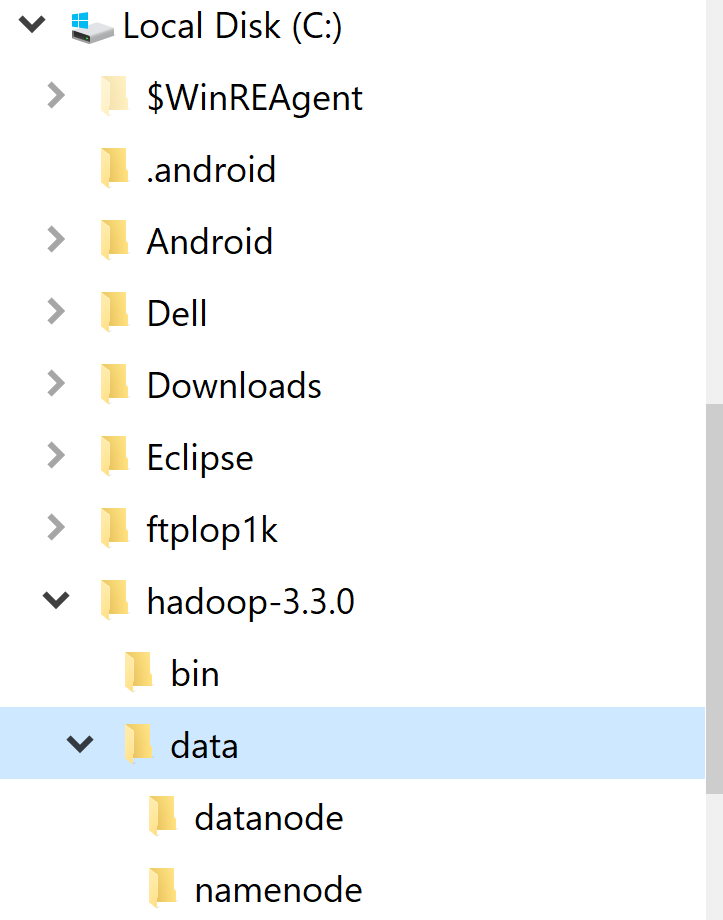
Sau đó cấu hình hdfs-site.xml như sau:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop-3.3.0/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop-3.3.0/data/datanode</value>
</property>
</configuration>
Cấu hình yarn-site.xml như dưới đây:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Cấu hình hadoop-env.cmd:
Mở file này lên và tìm tới lệnh:
- set JAVA_HOME=%JAVA_HOME%
sửa %JAVA_HOME% thành đường dẫn cài JDK trong ổ C:
- set JAVA_HOME= C:/jdk1.8.0_201
7) Cập nhật các Hadoop Configurations
Tải https://github.com/s911415/apache-hadoop-3.1.0-winutils
Tải về giải nén ra thấy thư mục bin ở bên trong
Chép đè thư mục bin này trong thư mục bin của C:\hadoop-3.3.0\bin
Sau đó format lại namenode và datanode: mở command line lên, gõ lệnh sau:
- hdfs namenode –format
- hdfs datanode -format
Bước format này chỉ cần làm 1 lần.
*Tiếp theo sao chép file:
“C:/hadoop-3.3.0/share/hadoop/yarn/timelineservice/ hadoop-yarn-server-timelineservice-3.3.0.jar”
vào “C:/hadoop-3.3.0/share/hadoop/yarn/hadoop-yarn-server-timelineservice-3.3.0.jar”
8) Hoàn thành cài đặt Hadoop và test thử nghiệm với start-all.cmd
Để test Hadoop, ta mở command line và di chuyển tới thư mục
C:/hadoop-3.3.0/sbin
Sau đó gõ lệnh:
- Start-all.cmd
Chi tiết xem hình các lệnh dưới đây:

Sau khi gõ lệnh trên, hệ thống sẽ chạy Hadoop
Phải đảm bảo các ứng dụng sau được chạy:
– Hadoop Namenode
– Hadoop datanode
– YARN Resource Manager
– YARN Node Manager
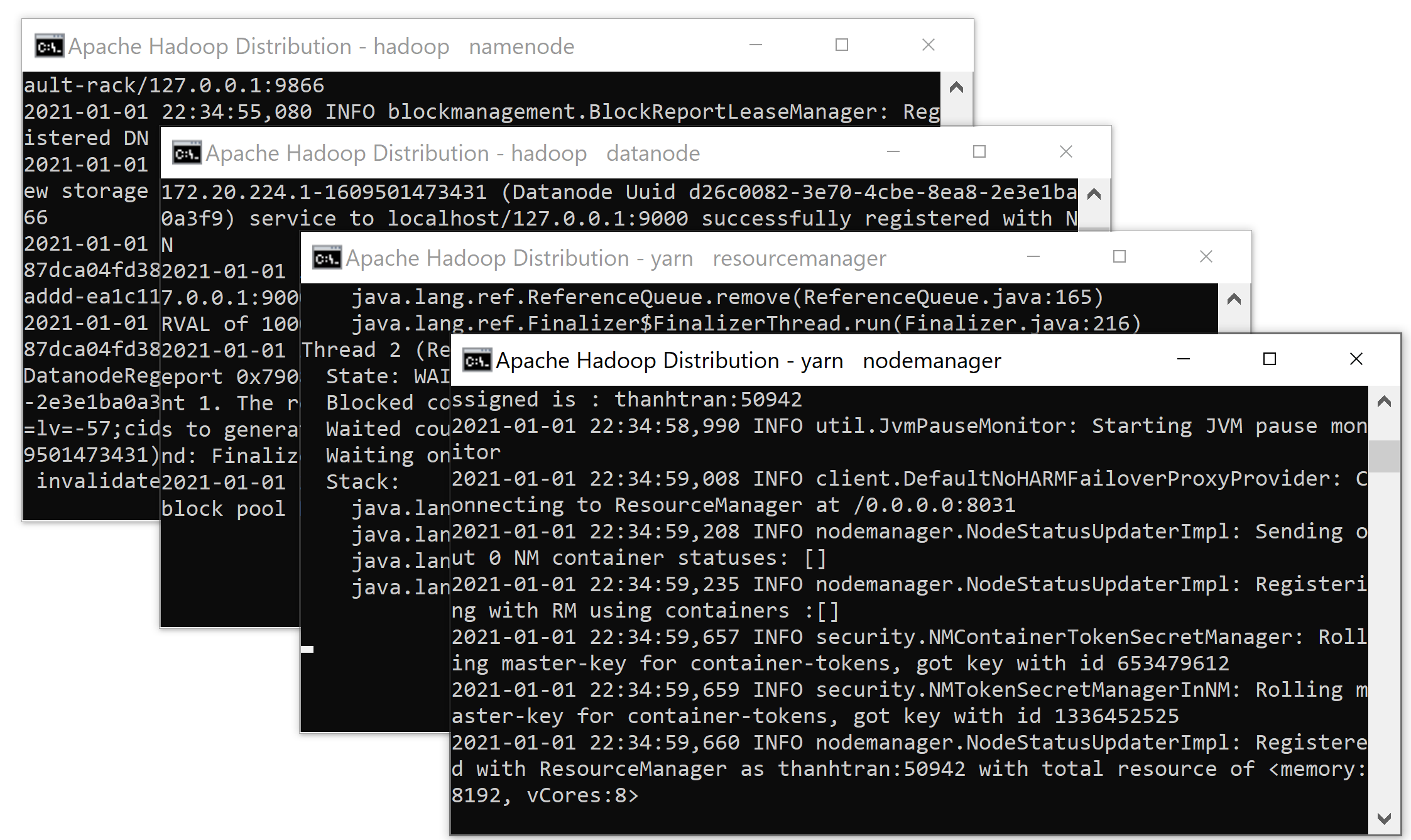
Như vậy ta đã khởi động thành công:
vào http://localhost:8088
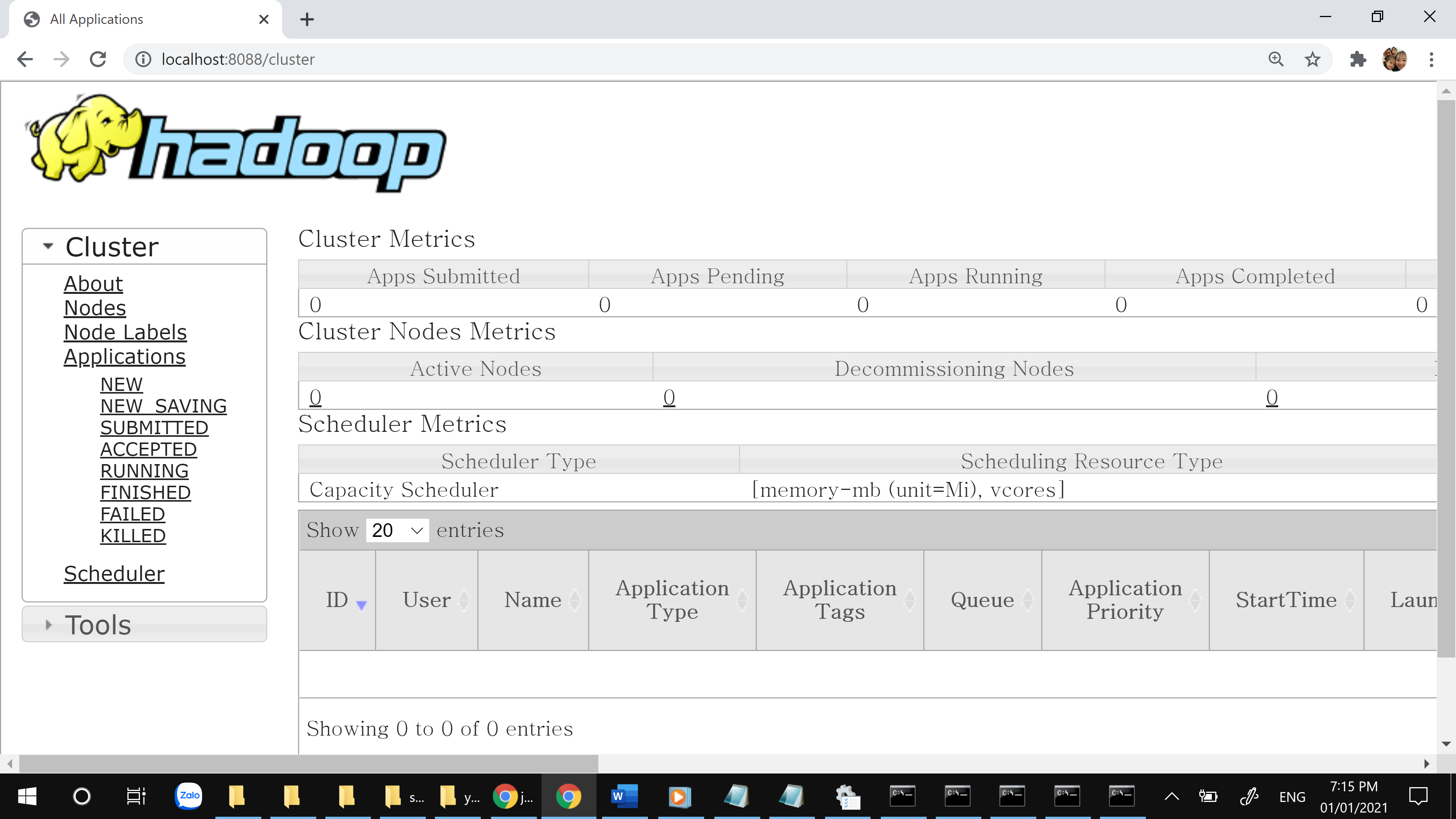
vào http://localhost:9870
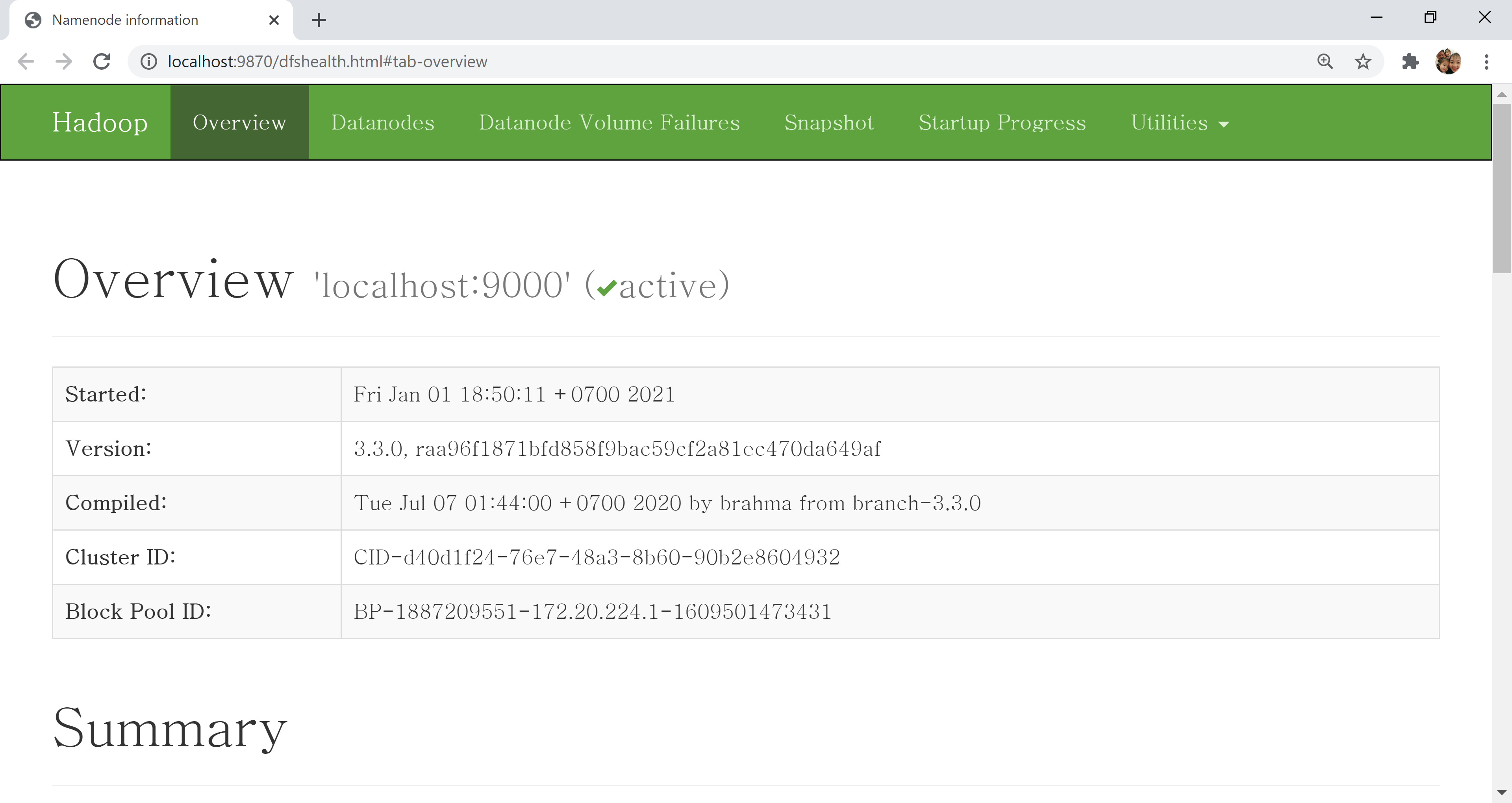
Như vậy ta đã test thành công
Ngoài ra ta có thể tách chạy 2 lệnh:
– Khởi động namenode và datanode :
start-dfs.cmd
– Khởi động yarn bằng lệnh:
start-yarn.cmd
Như vậy Tui đã hướng dẫn chi tiết xong từng bước cách thức cấu hình Hadoop trên Windows. Các bài sau Tui sẽ trình bày cáhc thức chạy một số giải thuật trên Hadoop này.
bản PDF của toàn bộ hướng dẫn này tải ở đây
Chúc các bạn thành công.
e làm đến bước cuối nhưng k mở được localhost a ơi
Mình cũng thế nào truy cập đc localhost:8088 được. Có cách nào xử lý ko admin
ad ơi mình cũng làm đến cuối nhưng cũng không truy cập được localhost. ???